源内とは?「政府版ChatGPT」ではなく、行政向けAIアプリ基盤
源内は、デジタル庁が内製開発した政府職員向けの生成AI利用環境です。デジタル庁の政策ページでは、2025年5月にデジタル庁全職員向けに運用が始まり、国会答弁検索AIや法制度調査支援AIといった複数のアプリケーションを提供することで、行政現場での検証が進められてきたと説明されています。
名称の由来は「Generative AI(GenAI)」の音を漢字に当てつつ、江戸時代の発明家・平賀源内を意識したもの、と公式に説明されています。読み方は「げんない」です。
源内の構成
源内は、ざっくりと2つのレイヤに分かれます。
- 汎用AIアプリ:対話型チャット、文章作成、要約、校正、翻訳、画像生成、音声文字起こしなど
- 行政実務用AIアプリ:法制度調査、国会答弁検索、補助金制度調査、パブコメ分類、会議記録作成など
ポイントは、「源内 = チャットUIを置いただけ」ではない点です。業務特化AIアプリを載せる基盤として設計されており、チャット機能は数あるアプリの一つにすぎません。
利用実績
デジタル庁が公開している運用実績は、開発者にとっても分かりやすいエビデンスです。
- デジタル庁職員の約8割が利用
- 延べ6万5,000回以上の利用
- 行政実務向けAIアプリは20種類以上が稼働
- 内部のLLMはAmazon Nova Lite、Claude、OpenAIなどを組み合わせ
「導入したけど誰も使わない」では終わっていない、という点だけでも、行政DX案件を考えるときの参考事例として価値があります。
なぜ18万人規模で実証するのか
デジタル庁は、令和8年度(2026年度)において、全府省庁の約18万人の政府職員を対象とした大規模実証を実施するとしています。実証期間は2026年5月から2027年3月までで、2027年度以降の本格的導入につなげる位置づけです。
背景にあるのは、おおまかに次の3点です。
- 少子高齢化による行政現場の担い手不足
- 公共サービスの維持・強化に向けた業務効率化の必要性
- 「政府自らがAIを先導的に利活用する」という基本計画の方針
注目すべきは、ここで「18万人にChatGPTライセンスを配る」のではなく、自前のAI基盤を作って配布するという選択を取っている点です。プロンプトの内容、利用ログ、機密性の制御、参照データの限定など、政府業務として外部SaaSに丸投げできない要件が多いことが、内製化の根拠になっています。
OSS公開で何が変わるのか
2026年4月24日、デジタル庁は源内の一部を商用利用可能なライセンスのもと、GitHub上でOSSとして公開しました。
公開された範囲
- 源内Webのソースコードと構築手順:digital-go-jp/genai-web
- 行政実務用AIアプリの開発テンプレート・実装:digital-go-jp/genai-ai-api
- 行政実務用RAGの開発テンプレート(AWS)
- LLMをセルフデプロイして利用する開発テンプレート(Azure)
- 最新の法律条文データを参照し回答する法制度AIアプリの再現可能な実装(Google Cloud)
ライセンスは、ソースコードがMIT、ドキュメントがCC BY 4.0です。商用利用も可能なので、自治体・SIer・民間企業がそのまま事業に組み込める形になっています。
注意点:公開「対象」にも線引きがある
OSS化されているのは「Webインターフェース」と「一部のAIアプリのテンプレート・実装」までです。本番運用に必要な内部マニュアル、各種機密性のある運用設定、利用しているLLMの個別契約条件などは、当然ながら公開対象外です。
リポジトリ運用にも特徴があります。
- Pull Requestは受け付けていない
- Issueは「データ損失や破損」「JIS X 8341-3:2016 AA相当のアクセシビリティ重大障壁」など致命的なケースのみ
- 永続的なメンテナンスは保証されておらず、将来的に公開を終了する可能性も明記
つまり源内OSSは「みんなで一緒に育てるOSS」というより、「政府が現場で動かしている設計の参照実装を、商用OKで開示する」スタンスに近いと読めます。コードを丸ごと取り込むのではなく、自治体・SIerが自前のAI基盤を作るときの設計の手本として使う、というのが現実的な扱い方です。
開発者が注目すべきポイント
ここからが、一番おもしろい部分です。源内のリポジトリを読むと、汎用ChatGPTアプリのテンプレートと、政府AI基盤との設計思想の違いが見えてきます。
1. 源内Webは AWS GenU をベースに「本番運用前提」で拡張
源内WebリポジトリのREADMEには、次のような自己紹介があります。
- AWS製OSS「Generative AI Use Cases(GenU)」をベースに、変更・機能追加を行ったもの
- GenUとは独立して開発しており、機能構成も異なる
- チーム管理、AIアプリ管理、デザインシステム適用などを追加
- 画像生成ページのパラメータ調整機能には、アクセシビリティ上の課題が残存
ここから読み取れるのは、源内Webは「PoC用のサンプルアプリ」ではなく、監視やモニタリングまで含めて運用しやすいよう作り変えた現場向けGenU派生だという点です。
検証ブログによれば、デプロイ自体はGenUと同じAWS CDKベースで、CloudFront / Cognito / API Gateway / Lambda / DynamoDB / S3 / Bedrockなどが組み合わされています。チーム管理機能やAIアプリ一覧表示などは追加のセットアップスクリプトの実行が必要、という細かな運用上の差分も入っています。
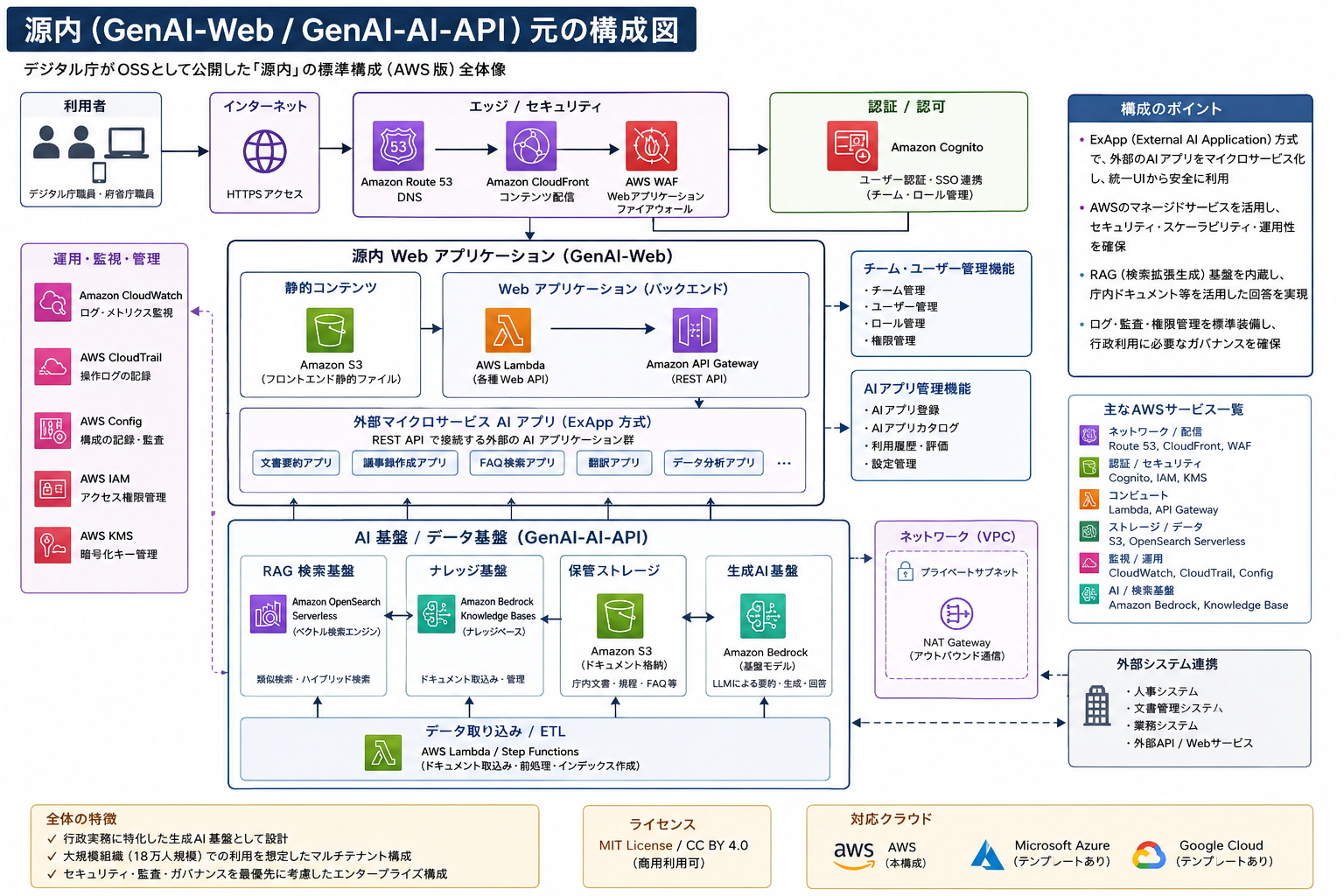
2. 「ExApp」方式:REST APIで外部マイクロサービスを束ねる
源内のもう一つの重要な特徴が、ExApp(外部AIアプリ)方式です。
- 行政実務用AIアプリは、源内Webとは独立した環境で構築できる
- REST APIのプロトコルに準拠すれば、GUIから源内への追加登録ができる
- AWSに限らず、Azure、Google Cloud上で構築したAIアプリも、源内のUIから統一的に利用できる
これはGenUのBedrock AgentsやMCPを活用するアプローチとは異なる設計です。源内は REST APIを介した外部マイクロサービス としてAIアプリを束ねる方式を選んでおり、結果としてマルチクラウド前提のAIアプリ統合基盤になっています。
実際、genai-ai-apiリポジトリには、
- AWS(クエリ拡張RAG)
- Azure(vLLMセルフデプロイ)
- Google Cloud(法制度AIアプリ)
の3クラウドに対応したテンプレートが収録されています。「特定クラウドにロックインしない設計」を、政府が公式参照実装として示した、という点は意義が大きいです。
3. 認証・セキュリティ・データ分離
開発者が見るべきポイントとしては、認証・セキュリティ周りも見逃せません。
- 政府統一基準に準拠したセキュリティを前提とし、機密性2情報を含むプロンプトの入力に対応
- ガバメントソリューションサービス(GSS)ポータルからのSSOで利用
- ソースコード上では、S3のキー先頭にCognito Identity Poolの
identityIdを組み込み、{identityId}/{uuid}/{filename}形式でユーザーごとに分離されたディレクトリ構造を構築
「機密性2情報を扱うAIチャット」という要件は、企業の社内AIアプリにそのまま読み替え可能です。Cognito Identity PoolによるS3のユーザー単位プレフィックス分離など、社内AIアプリの権限設計を考えるときの参考になります。
4. RAGテンプレートと法制度AI
genai-ai-apiの中身は、開発者にとってかなり実用的です。
- 行政実務用RAG(AWS):内部規則・通達・行政文書を参照するRAG。クエリ拡張つき
- LLMセルフデプロイ(Azure):vLLMなどを使い、AIモデルを自組織環境に直接デプロイ。データを外部に出さずに運用したいケース向け
- 法制度AIアプリ(Google Cloud):最新の法律条文データを参照するRAG実装
この3点セットは、そのまま「企業内RAGをどう作るか」の議論に転用できます。法令データという可変・差分の激しいコーパスをどう扱うか、機密データを外に出さない構成として何を選ぶか、という観点で読むと学びが多いリポジトリです。
5. 国産LLMとの接続前提
2026年3月、デジタル庁は源内で試用する国産LLMの公募結果を公表し、15応募から7件を選定しました。
- NTTデータ
- KDDI・ELYZA共同応募体(Llama-3.1-ELYZA-JP-70B)
- ソフトバンク(Sarashina2 mini)
- 日本電気(cotomi v3)
- 富士通(Takane 32B)
- Preferred Networks(PLaMo 2.0 Prime)
- カスタマークラウド(CC Gov-LLM)
選定されたLLMは源内上で試用評価され、令和9年度(2027年度)にはこの評価を踏まえて政府調達(有償)を検討するとされています。
ここで重要なのは、「源内は単一LLMにロックインしない構造」を前提にしている点です。OpenAI、Anthropic Claude、Amazon Nova、そして国産LLMが、同じ源内基盤の上で並行して評価されることになります。マルチLLM前提でアプリを書くという考え方は、企業AIアプリ設計でも今後ますます重要になります。
注意点:OSS公開=そのまま政府AIが使える、ではない
最後に、誤解されがちな点を整理しておきます。
- OSS公開は「源内のソースコード一部の開示」であって、政府の運用環境そのものへのアクセス権ではない
- 商用利用可だが、自前のクラウド(AWS / Azure / Google Cloud)の構築・運用費用は別途かかる
- 本番導入には、認証、ログ管理、権限管理、監査、データ取り扱いの契約整理など、技術以外の整備が必須
- AIの回答をそのまま正解として扱わない運用設計(人間レビュー、出典提示、再質問の仕組みなど)が引き続き重要
特に自治体や中堅以上の企業で導入を検討する場合は、ライセンスの確認に加えて、ログの所在、機密データの扱い、外部APIへの送信範囲を契約段階で詰める必要があります。
まとめ
源内は「政府版ChatGPT」ではなく、行政実務向けのAIアプリ基盤として設計された政府AIです。
- 2025年5月にデジタル庁全職員向けに運用開始、約8割の職員が利用する実需付きの基盤
- 2026年度に全府省庁約18万人で大規模実証を実施
- 2026年4月24日にWebインターフェースとAIアプリテンプレートをOSS公開(MIT / CC BY 4.0)
- 源内WebはAWS GenUベース、行政実務用AIアプリはAWS / Azure / Google Cloud対応の3テンプレート構成
- ExApp方式により、REST APIで外部マイクロサービス化されたAIアプリを統一UIに束ねる
- 国産LLM 7社が源内上で試用評価され、2027年度の政府調達につながる
開発者・SIer・自治体DX担当者にとって、源内は次の二つの意味で重要な題材です。
- 行政AI基盤として、自治体や公共系業務委託の調達仕様を設計する際の参照モデルになる
- 業務特化AIアプリ基盤として、kintoneや社内システムと組み合わせた企業向けAI設計の参考になる
「政府がここまで設計を公開してくれた」という事実は、日本の生成AI実装の議論を一段押し上げる出来事だと言えます。リポジトリを覗いてみると、ベタ書きで作ったRAGとは違う「運用前提の構造」が見えてくるはずです。