LLMを使った開発をしていると、OpenAIやClaude、Geminiといったメジャーどころに加えて、Llama系、DeepSeek系、Qwen系、GLM系、MiniMax系など、新しいモデルの選択肢が一気に広がっているのを実感します。気になるモデルが出るたびに「軽く触って挙動を確かめたい」と思っても、各社それぞれにアカウントを作って課金情報を登録していくのは、それなりに手間のかかる作業です。
そんなときに候補に入ってくるのが、NVIDIAが運営するモデルカタログ NVIDIA Build です。NVIDIAは自社GPU上で動くAIモデルをここにまとめて公開しており、その一部は Free Endpoint として無料でAPI試用できるようになっています。
さらに興味深いのは、Free Endpointの対象が NVIDIAの自社モデルだけでなく、Z.aiのGLM-4.7やMiniMaxのMiniMax M2.7など、外部開発元のモデルも含まれている という点です。Nemotron系の自社モデルだけが並んでいるのだろうと思って覗くと、想像以上に広いラインナップで驚くはずです。
本記事では、NVIDIA Build(NIMカタログ)のFree Endpointの仕組み、対象モデル、実際の使い方、そして無料利用時の注意点を整理します。
まず用語整理:NVIDIA BuildとNIMとFree Endpointの関係
最初に、混同しやすい3つの用語の関係を整理しておきます。
NVIDIA Build は、AIモデルを並べたカタログ/ポータルサイトです(URL: build.nvidia.com)。ここでモデルを探したり、Playgroundで試したり、APIキーを発行したりします。いわば「入口のUI」です。
NVIDIA NIM(NVIDIA Inference Microservices) は、モデルを最適化済みコンテナとしてパッケージ化する技術/サービス形態の名前です。自社環境にデプロイしてセルフホストもできるし、NVIDIAがホストしているものをAPIで叩くこともできます。NVIDIA Buildのカタログには、このNIM形式で動くモデルが並んでいます。
Free Endpoint は、NVIDIAホスト版NIMエンドポイントの中の課金区分/提供ステータスの1つで、「無料で叩けるNIM API」を意味するラベルです。NVIDIA Buildのカタログ画面では、フィルター項目として表示されます。
階層で書くと、こんな関係です。
NVIDIA Build(カタログ・入口)
└─ NIM(モデルの提供形態)
├─ セルフホスト型(自分のGPUで動かす)
└─ NVIDIAホスト型API
├─ Free Endpoint ← 無料枠
└─ 有償/エンタープライズ枠つまり「NVIDIA BuildのFree Endpoint」と言うときは、正確には 「NVIDIA Buildカタログから叩けるNIMホスト版APIのうち、Free Endpoint対象のもの」 を指しています。本記事でも、このニュアンスで「NVIDIA Build(NIMカタログ)のFree Endpoint」と表記していきます。
Free Endpointの仕組み
NVIDIA Buildのモデル一覧画面には、フィルター項目として Free Endpoint が用意されており、これにチェックを入れると無料で試せるエンドポイント対象のモデルだけが絞り込まれます。
Free Endpointの対象モデルは、ブラウザ上のPlaygroundでそのまま試せるほか、APIキーを取得すればOpenAI互換のChat Completions APIとして呼び出せます。位置づけはあくまで開発・検証・プロトタイピング用途で、レート制限など一定の制約があり、商用本番の無制限利用は前提とされていません。
「触って試す」「PoCを作る」「アプリのモック実装で繋ぎ込む」といった用途であれば、APIキー1つで手軽に動かせるのが魅力です。
NVIDIA Buildの使い方
ここからが本題です。実際にNVIDIA Buildを開いて、APIで叩けるようになるまでの流れを順を追って見ていきます。
1. アカウントを作成する
まずは build.nvidia.com を開き、画面右上の Login からアカウント登録を進めます。
メールアドレスを入力し、届いた認証コードを画面に入力、各種必要情報を入力して完了させます。
途中でAuth認証やデバイス認証を求められます。
少しステップは多いですが、入力していくだけで完了します。一度作ってしまえば、以降は同じアカウントでログインするだけで使えます。
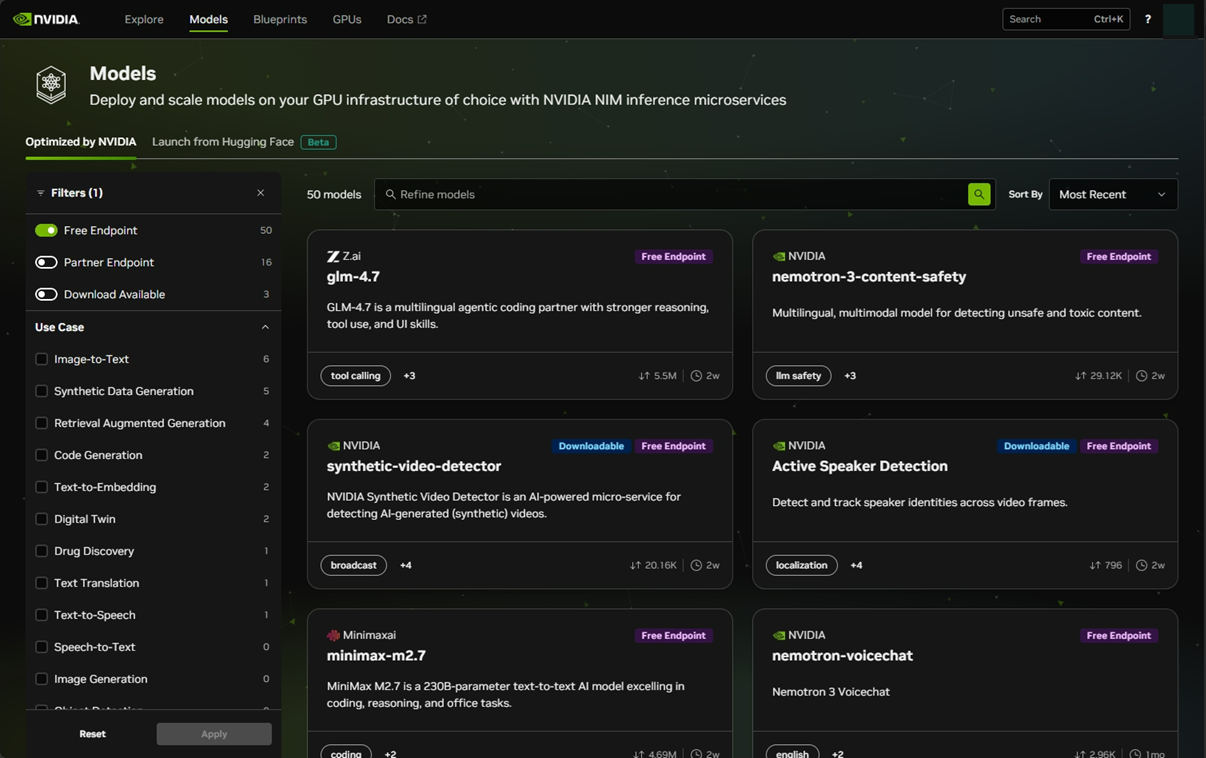
2. モデルを探す
ログイン後、トップページからモデルカタログを開きます。LLMだけでも、Llama系、Mistral系、DeepSeek系、Qwen系、GLM系、MiniMax系、そしてNVIDIA自身のNemotron系まで、選択肢は非常に広いです。
無料で試せるものに絞りたい場合は、左側のサイドバーまたはフィルターから Free Endpoint を選びます。これで、APIキー1つで叩けるモデルだけが一覧表示されます。検索バーから llama nemotron glm などのキーワードでも探せるので、目当てのモデルがあるなら直接打ち込むのが速いです。
3. Playgroundでまず触ってみる
気になるモデルをクリックすると、モデルカードが開きます。画面右側(または下部)にPlaygroundがあり、APIキーを発行する前にチャット形式で挙動を確認できます。
日本語のプロンプトに対する反応、コーディング系の指示への精度、長文での会話耐性、推論モードの有無などをここで軽く触ってから、API実装に進むかを判断するのがおすすめです。
4. APIキーを発行する
実際のアプリやスクリプトから呼び出すには、APIキーが必要です。発行手順は次のとおりです。
- 任意のモデル詳細ページ(例:
glm-4.7のページ)右上の View Code ボタンをクリック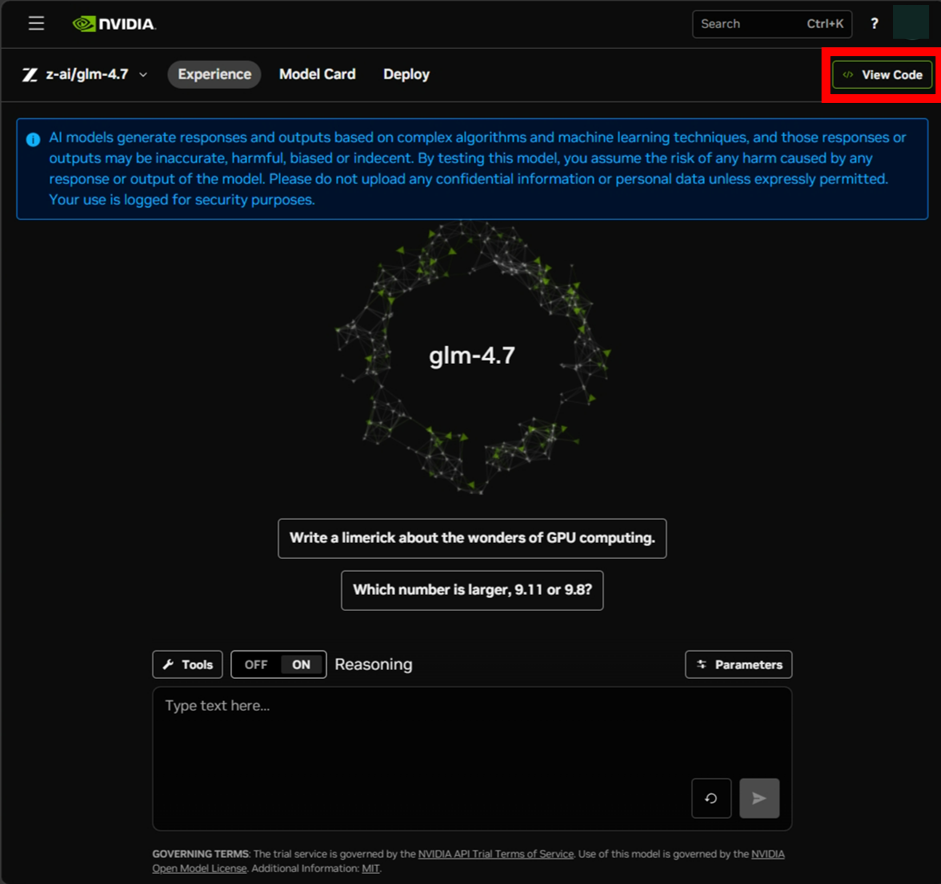
- 開いたウィンドウ内の Generate API Key ボタンをクリック
※追加の認証が必要になる場合があります。
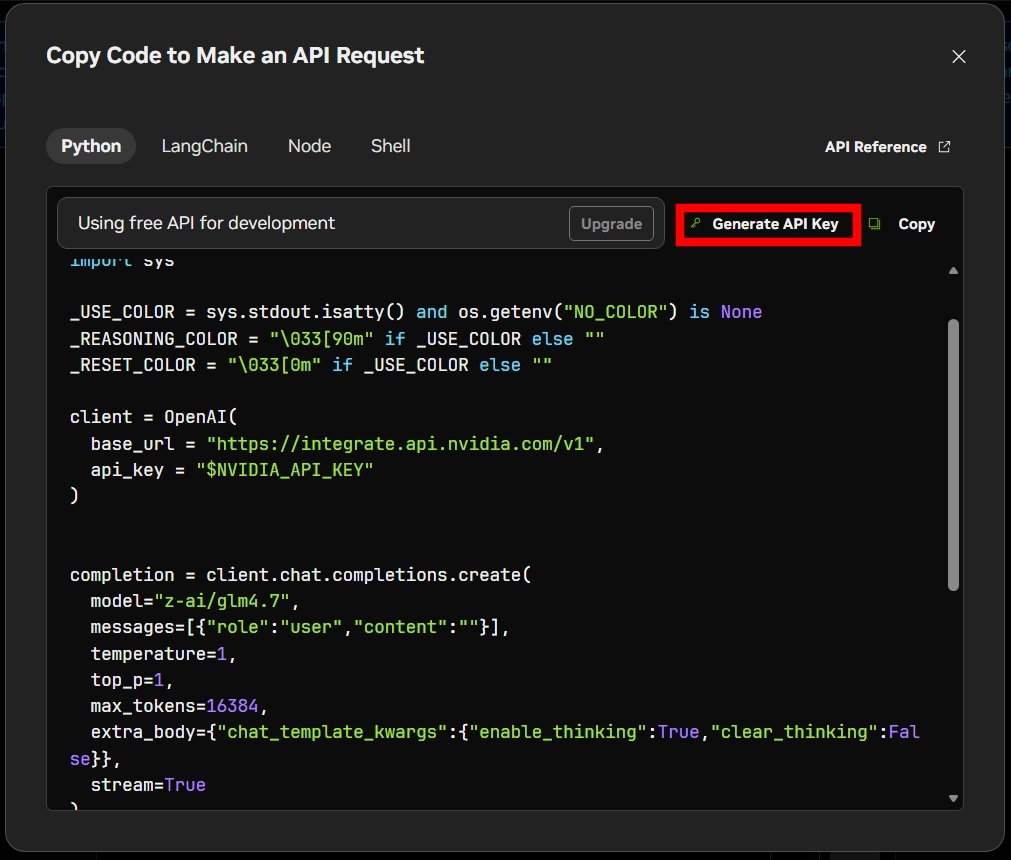
- 表示されたキーをコピーして、安全な場所に保存
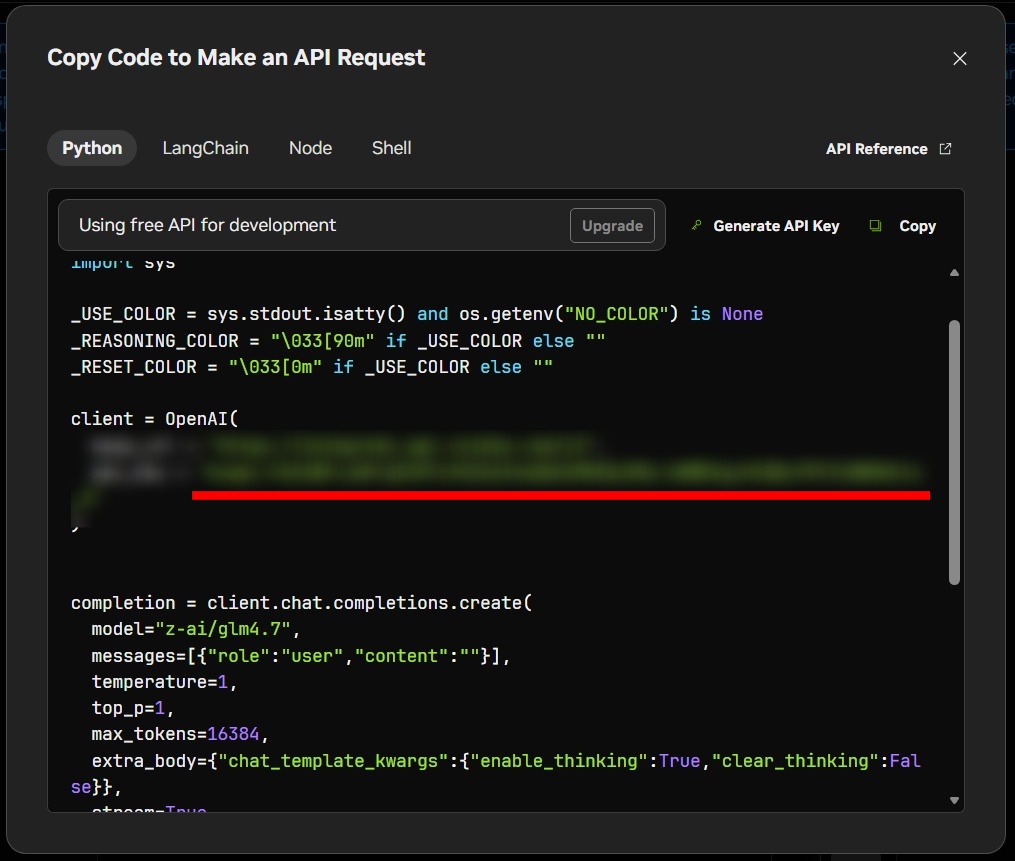
なお、同じAPIキーで NVIDIA Buildカタログ上の複数のNIMモデル を呼び出せます。モデルごとに別キーを発行する必要はありません。
5. OpenAI互換APIで呼び出す
NVIDIA NIMのAPIは、OpenAI互換のChat Completions形式で提供されています。代表的なエンドポイントは次のとおりです。
https://integrate.api.nvidia.com/v1/chat/completions
OpenAI互換ということは、openai Python SDKや、各種フレームワーク(LangChain、LlamaIndexなど)でbase URLとAPIキーを差し替えるだけで動かせる、ということを意味します。
Python + OpenAI SDKでの呼び出しサンプルです。
from openai import OpenAI
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key="YOUR_NVIDIA_API_KEY", # nvapi- で始まるキー
)
response = client.chat.completions.create(
model="", # モデルIDはNVIDIA Buildのカタログに従って指定
messages=[
{"role": "system", "content": "あなたは日本語で答えるアシスタントです。"},
{"role": "user", "content": "NVIDIA NIMの特徴を3つ教えて"},
],
)
print(response.choices[0].message.content)model に指定する文字列は、各モデルカードの「Run with API」「Get API Key」あたりのコードサンプルに表示されているモデルIDをそのまま使うのが確実です。OpenAI APIに慣れているチームであれば、移行コストはほぼゼロに近い感覚で試せます。
NVIDIA製ではないモデルもFree Endpointで提供されている
ここが今回の話題で一番面白い部分です。Free Endpoint対象には、NVIDIA以外のベンダーが開発したモデルも数多く含まれています。
GLM-4.7(Z.ai)
GLM-4.7は、中国のZ.aiが開発するLLMシリーズの1つです。NVIDIA Build上では、エージェント型のコーディング・推論パートナーとしての位置づけで紹介されており、多言語対応も特徴です。NVIDIA製ではないものの、NVIDIAのインフラ上でホストされ、Free Endpointとして無料で試せる状態になっています。
MiniMax M2.7(MiniMax / minimaxai)
MiniMax M2.7は、中国のMiniMaxが開発するモデルファミリーで、230Bパラメータ級の大規模テキストモデルとしてカタログに登録されています。確認時点ではFree Endpoint対象として掲載されていますが、NVIDIA Build上のモデルページでは「Deprecation in 12d」といった廃止予定の表示が出ている時期もあり、提供状況や提供形態は変わる可能性があります。利用を検討する際は、必ず最新のモデルページで現在の提供状態を確認してください。
このように、NVIDIA Buildのカタログは「NVIDIA製モデルだけを売る場」ではなく、NIM形式で動くモデルを束ねたハブ として機能しているのが分かります。一方で、外部モデルは提供元の判断で予告なく入れ替わる可能性もある、という点は意識しておきたいところです。
NVIDIA製モデルの代表格:Nemotron 3 Nano Omni
もちろん、NVIDIA自身が開発したモデルもラインナップに並んでいます。代表例が Nemotron 3 Nano Omni です。
NVIDIAの公式ブログによれば、Nemotron 3 Nano Omniは30B-A3BのハイブリッドMoE構成で、Transformer-Mamba系のハイブリッドアーキテクチャを採用したマルチモーダルモデルです。テキスト・画像・動画・音声を扱うことができ、重み・データセット・学習レシピも公開された オープンウェイトモデル になっています。オープンウェイトかつマルチモーダルという、近年のNVIDIAらしい方向性のモデルです。
ただし、NVIDIA Build上での表示はページによって揺れがあり、Notebookページでは「Free Endpoint」として扱われる一方、モデルカードや一覧では「Downloadable」と表示される箇所もあります。実際にAPIで叩けるかどうかは、利用前にモデルページの最新表示で確認するのが安全 です。
「無料」の意味を勘違いしないために
ここまで読むと「全部無料で済むなら本番でも使えるのでは?」と思いたくなりますが、ここは少し冷静に区別しておきたいところです。
NVIDIA Developer Programの説明では、NVIDIA-hosted NIM API endpointsは 開発・テスト用途で利用できるリソース という位置づけです。NVIDIA Developer Forumでも、無料ティアのAPIアクセスにはモデル・用途・全体トラフィックに応じたレート制限がかかると説明されています。
そして実際に触ってみるとすぐに気づくのですが、Free Endpointは基本的にレスポンスがかなり遅いです。利用者数や同時アクセス数に対してリソースが潤沢に割り当てられているわけではないため、混雑する時間帯では1リクエストの応答に数十秒かかることも珍しくありません。動作確認や挙動の比較といった「軽く触る」用途では問題になりませんが、ストリーミングUI込みのデモを作るような場面では、想定どおりの体感が出にくい可能性があります。
実務で意識しておきたい注意点を整理すると、商用本番運用での安定性は別途検証が必要ですし、レート制限や混雑時の応答遅延によって想定したスループットが出ない場合もあります。無料提供条件は予告なく変更され得るため、モデルごとに提供可否や扱いが変わる可能性も常にあります。
そして特に注意したいのが、各モデルのライセンスや利用規約です。Free Endpointだからといって、その出力を商用サービスに自由に組み込めるとは限りません。各モデルのライセンス条項は、必ず個別に確認してください
どう使い分けるとよいか
実際に手を動かす立場で考えると、NVIDIA Build(NIMカタログ)のFree Endpointは、新しいモデルの素の挙動をPlaygroundで素早く確認したいときや、OpenAI / Claude / Gemini以外のモデルを最小工数で比較検証したいときに特に役立ちます。社内ツールのPoCでコストを気にせずプロトタイプを動かしたい場面や、中国系モデル(GLM、MiniMaxなど)の日本語力や挙動を評価したい場面でも有用です。
逆に、ユーザートラフィックを抱える本番アプリのバックエンドとして据えるのであれば、NIMの セルフホスト や、NVIDIA以外も含めた商用APIプランの利用、SLA付きの推論サービスの検討が現実的になります。
まとめ
NVIDIA Build(NIMカタログ)のFree Endpointは、NVIDIA製のNemotron系に加え、Z.aiのGLM-4.7やMiniMax M2.7など外部モデルまで、OpenAI互換APIで気軽に試せる 強力な検証環境です。アカウント作成からAPIキー発行までの手順もシンプルで、既存のOpenAI連携コードがあれば数行の書き換えで動かせます。
一方で、無料枠は本番で使い倒すためのものではなく、レート制限や利用条件、各モデルのライセンスを踏まえた使い分けが前提になります。NVIDIA Build上の提供状態(Free Endpoint表示・廃止予定の有無など)はモデルやページによって変わり得るため、利用前に最新のモデルページで確認するのが安全です。
新しいモデルが出るたびに「とりあえず触ってみる」場所として、NVIDIA Buildを開発者の引き出しに加えておくと、AI関連の意思決定がぐっとやりやすくなるはずです。
参考リンク
- NVIDIA Build Models: https://build.nvidia.com/models
- NVIDIA NIM for Developers: https://developer.nvidia.com/nim
- NVIDIA Developer Blog(Nemotron 3 Nano Omni): https://developer.nvidia.com/blog/nvidia-nemotron-3-nano-omni-powers-multimodal-agent-reasoning-in-a-single-efficient-open-model/
- NVIDIA API Docs(Chat Completions): https://docs.api.nvidia.com/nim/reference/create_chat_completion_v1_chat_completions_post
- NVIDIA Developer Forums(NIM Access & Accounts): https://forums.developer.nvidia.com/c/ai-data-science/nvidia-nim/access-accounts/699