Ollamaとは?ローカルでLLMを動かす方法・API・Modelfileの基本を解説
Ollama(オラマ)は、macOS / Windows / Linux でオープンソース / オープンウェイトのLLM(例:Gemma、Qwen、Llama系など)を手元のマシンで実行しやすくするためのツールです。
- ターミナルから
ollama run ...のようにモデルを起動してチャットできる - ローカルで HTTP API(既定:
http://localhost:11434) を提供し、アプリから呼び出せる Modelfileで プロンプトやパラメータを固定した“自分用モデル” を作れる
この記事では、初心者向けに「何ができるか」「どう始めるか」「どうアプリ連携するか」を最短で押さえます。
できること(ざっくり)
- ローカルLLMの実行:モデルをダウンロードして対話
- REST APIで連携:自作アプリ、社内ツール、検証スクリプトから呼び出し
- モデルのカスタマイズ:
Modelfileで温度・コンテキスト長・システムメッセージ等を設定 - 既存ツールとの統合:ドキュメント上は Claude Code / Codex / OpenClaw などの起動(launch)も案内されています
インストール(最短)
OllamaはOSごとにインストールできます(macOS / Windows / Linux)。
- ダウンロード:https://ollama.com/download
インストール後、まずはターミナルで ollama を実行します。クイックスタートでは、ollama を起動すると対話的なメニューが開く形になっています。
ollama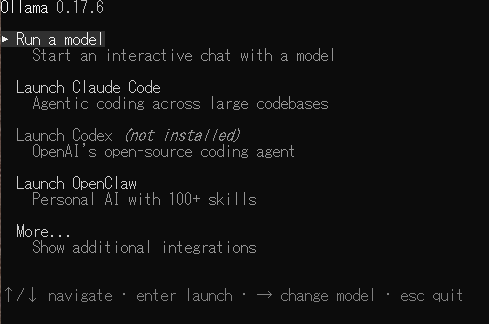
まずはモデルを動かす(CLI)
最初にやることは「モデルを指定して実行する」です。README例では、例えば Gemma を次のように実行します。
ollama run gemma3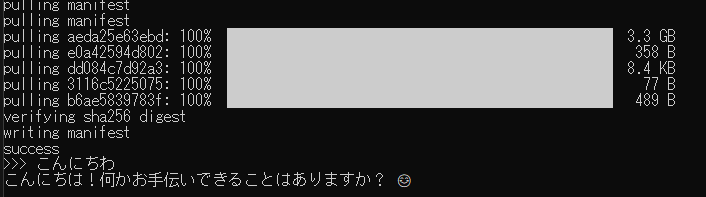
モデルの一覧はライブラリから探せます:
補足:モデルはサイズが大きいことが多いので、ストレージ容量・メモリ・GPUの有無で体験が変わります。まずは小さめモデルで試すのが無難です。
目安として7Bモデルには少なくとも8GB RAM、13Bには16GB、33Bには32GBが必要になります。
OllamaのAPIでアプリから呼ぶ
OllamaはローカルにHTTP APIを立ててくれます。ドキュメントによると、既定のBase URLは次の通りです。
- ローカル:
http://localhost:11434/api
例:/api/generate(プロンプト→生成)
curl http://localhost:11434/api/generate -d '{
"model": "gemma3",
"prompt": "Why is the sky blue?"
}'
例:/api/chat(メッセージ→チャット)
curl http://localhost:11434/api/chat -d '{
"model": "gemma3",
"messages": [{ "role": "user", "content": "Hello!" }]
}'
ポイント:レスポンスの速度や出力の質感もCLIで先に確認しておくと、APIで組み込む際のイメージがつかみやすいです。
Python / JavaScript から呼ぶ
Ollamaには公式ライブラリが案内されています。
READMEの最小例(イメージ):
Python
from ollama import chat
response = chat(
model='gemma3',
messages=[{'role': 'user', 'content': 'Why is the sky blue?'}],
)
print(response.message.content)
JavaScript
import ollama from 'ollama'
const response = await ollama.chat({
model: 'gemma3',
messages: [{ role: 'user', content: 'Why is the sky blue?' }],
})
console.log(response.message.content)
Modelfileで“自分用モデル”を作る
Ollamaの強いところの1つが Modelfile です。ドキュメントでは、Modelfileは「カスタムモデルを作って共有するための設計図」と説明されています。
何ができる?
- ベースモデル(FROM) を指定する
- 温度、コンテキスト長などの パラメータ(PARAMETER) を固定する
- SYSTEMメッセージを入れて、キャラやルールを固定する
- TEMPLATEでプロンプト構造をカスタムする
最小のModelfile例
FROM llama3.2
PARAMETER temperature 1
PARAMETER num_ctx 4096
SYSTEM You are Mario from super mario bros, acting as an assistant.
作成→実行の流れ(ドキュメント例):
Modelfileを保存ollama create <モデル名> -f ./Modelfileollama run <モデル名>
どんなときにOllamaが便利?(ユースケース)
- ローカルで検証したい:プロンプトやワークフローの実験を手元で回したい
- 社内利用の下準備:まずは個人環境でRAGや要約機能を試す
- 開発中のアプリに組み込みたい:HTTP APIで簡単にLLM呼び出しを追加したい
- プロンプトを固定したい:Modelfileで“用途別モデル”を作ってチームで共有したい
注意点(初心者がハマりやすい)
- マシンスペック依存:モデルが大きいほど、メモリ・GPUで体験が変わります
- モデル選定が重要:まずは小さめモデルで動作確認→用途に合わせて乗り換えが安全
- セキュリティ/データ取り扱い:ローカルとはいえ、扱うデータの機密性には注意(ログやキャッシュも含む)
まとめ
- Ollamaは、ローカル環境でLLMを動かし、CLIとHTTP APIで使えるようにするツール
- 初心者は
ollama run <model>→curl http://localhost:11434/api/...の順で試すと理解が早い Modelfileを使うと、用途別に設定を固定した“自分用モデル”を作れる
参考(公式・一次情報)
- Ollama公式:https://ollama.com/
- Quickstart:https://docs.ollama.com/quickstart
- API:https://docs.ollama.com/api
- Modelfile:https://docs.ollama.com/modelfile
- GitHub:https://github.com/ollama/ollama